為 OpenClaw 打造 LanceDB 記憶插件
OpenClaw 內建記憶不夠可靠?用 LanceDB 打造混合檢索、多 scope 隔離、噪聲過濾的記憶插件。
我花了一個小時帶 OpenClaw agent 走過一整套部署環境 — VPN tunnel、非標準 port、auth/middleware.ts 裡那個只在高負載才會浮現的 race condition。下一次 session,全部消失。Agent 完全不記得這些事。
OpenClaw 用 Markdown 檔案來存記憶。在一定程度內能用,但超過就不行了。Model 自己決定什麼值得存,這代表它會固定漏掉你覺得重要但它沒意識到的細節。社群開發的 memory-lancedb-pro 插件把整個記憶子系統換掉 — 用向量資料庫搭配混合檢索、scope 存取控制和自動噪聲過濾取代平面檔案。我在日常工作流中跑了一段時間。這篇文章拆解它內部的工程設計、程式碼實際在做什麼(我讀過了),以及設計上真正的 trade-off。
OpenClaw 記憶系統的瓶頸在哪
OpenClaw 預設的記憶把資訊存在兩個地方:MEMORY.md 放策展過的長期知識,memory/YYYY-MM-DD.md 放每日 session log。都是純 Markdown。底層的記憶插件把這些檔案索引到每個 agent 專屬的 SQLite 資料庫(約 400 token chunk,80 token overlap),並透過 memory_search 支援搜尋 — 包含向量相似度和 BM25 關鍵字匹配。
所以檢索引擎本身不是問題。問題出在周圍的一切。
Agent 控制什麼被保存。 記憶捕獲是 LLM 驅動的 — model 自己決定什麼值得寫入 MEMORY.md。實際上它會固定漏掉微妙的細節:隨口提到的 port number、描述過一次的 workaround、某個 env var 的名稱。這些細節很重要。Model 不知道它們重要。
Context compaction 侵蝕已注入的記憶。 當對話接近 context window 上限,OpenClaw 會壓縮舊訊息。磁碟上的記憶檔案不受影響 — 但先前檢索並注入對話的 context 會在壓縮過程中被摘要或丟棄。下次 agent 需要那個事實時,它必須重新檢索,前提是它知道要去找。有個 memoryFlush 機制可以在壓縮前觸發寫入,但不是完整的解決方案。
召回是 opt-in 的。 memory_search 只在 agent 自己決定呼叫時才會觸發。沒有自動檢索代表相關事實靜靜躺在索引裡,agent 卻用不完整的資訊自信地工作。你可以用 system prompt 指示 agent 更積極地搜尋記憶,但你仍然依賴 model 去穩定地遵守指令。
這些不是 bug,是為了簡潔和低資源消耗做的架構選擇。對單一 agent、偶爾遺忘可以忍受的場景,內建系統夠用。但當你需要可靠的跨 session recall — 跑多 agent pipeline、或你的 agent 處理的基礎設施中一個忘記的 credential 路徑就代表凌晨三點被 page — 你需要更結構化的方案。
為什麼選 LanceDB
在深入檢索 pipeline 之前,值得問:為什麼偏偏是 LanceDB?
LanceDB 是一個嵌入式、serverless 的向量資料庫,建構在 Lance 欄位格式(基於 Apache Arrow)之上。它在 process 內運行 — 不需要獨立 server、不需要 Docker container、不需要 managed service。把它想成向量版的 SQLite。它從磁碟 memory-map 檔案並用 SIMD 優化查詢,處理 2 億以上的向量,原生支援 ANN 向量搜尋和 BM25 全文搜尋。
對 agent 記憶來說,嵌入式架構幾乎是完美契合。Agent 記憶資料庫通常很小 — 幾千到幾萬筆。你不需要 Qdrant 的分散式叢集或 Pinecone 的託管基礎設施。你需要的是瞬間啟動、零維運、跟 agent process 共存的東西。LanceDB 恰好如此,而且它原生的混合搜尋意味著你不需要另外接一個全文引擎。
主要限制:LanceDB 的全文搜尋不支援布林運算子(AND、OR),生態系也比 Qdrant 或 Chroma 年輕。對 agent 記憶的工作負載來說,兩者都不是問題。
混合檢索 Pipeline
純向量搜尋處理語義相似度很好 — 它知道「跑 gateway 的那台機器」跟「gateway host」是同個意思。但對精確匹配就不行。Error code、IP 位址、函式名稱、config key — 這些沒有有意義的語義鄰居,需要關鍵字匹配。
memory-lancedb-pro 插件跑一個多階段檢索 pipeline,融合向量和關鍵字信號,再透過一系列後處理來壓制噪聲和過時結果。以下是程式碼實際在做的事。
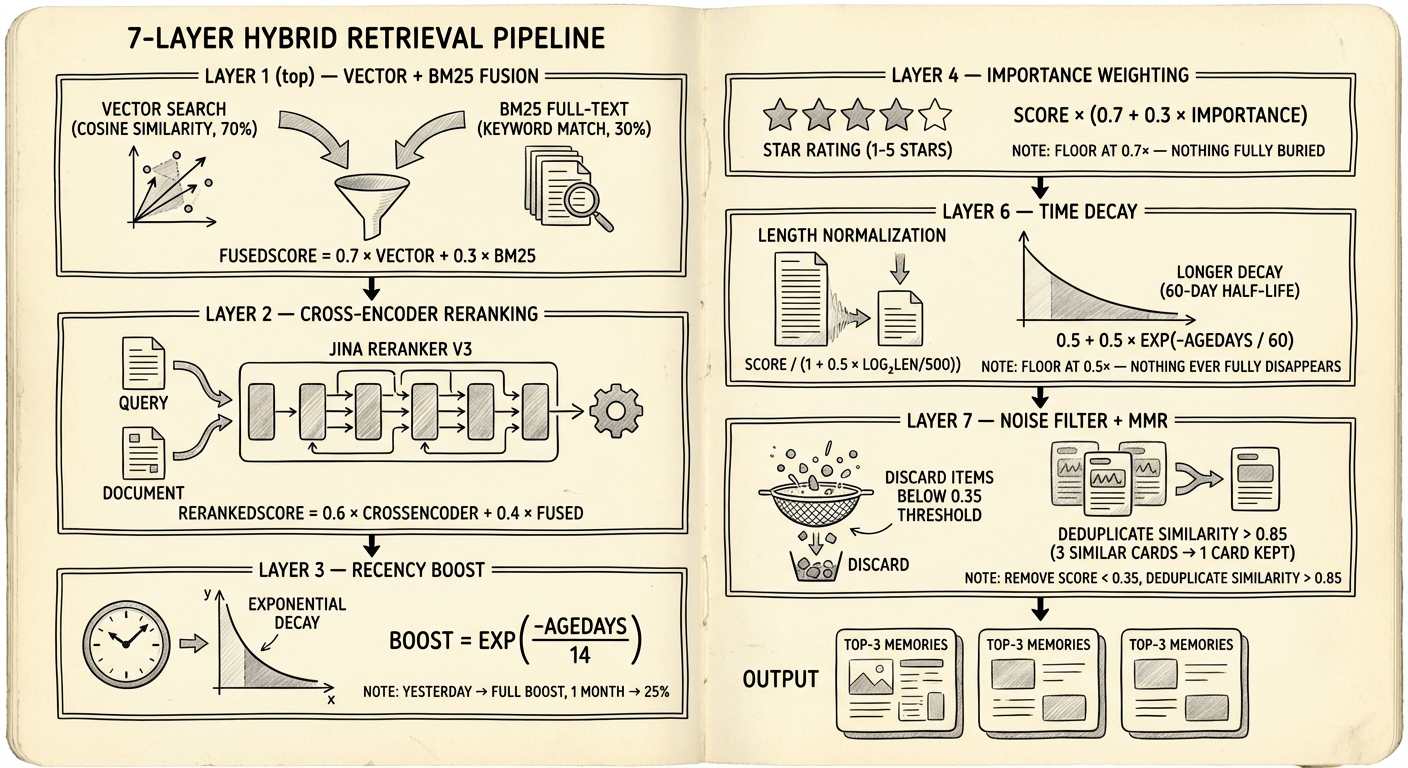
第 1 階段:向量 + BM25 融合
每個 query 透過 Promise.all() 同時跑向量搜尋(LanceDB ANN 的 cosine similarity)和 BM25 全文搜尋。融合方式不是大多數 RAG 教學裡那種傳統加權和。讀 retriever.ts 的實際程式碼,插件用的是乘法式的 BM25 加成:
fusedScore = vectorScore + (bm25Hit ? 0.15 × vectorScore : 0)
如果一筆結果同時出現在向量和 BM25 結果中,會得到 15% 的分數加成。如果只出現在 BM25(沒有向量匹配),直接用原始 BM25 分數。這跟經典的 α × vector + (1-α) × bm25 公式不同 — 插件的 README 描述為「超越傳統 RRF 的調校」。
值得注意:config 暴露了 vectorWeight 和 bm25Weight 參數(預設 0.7/0.3),但這些實際上沒被用在融合計算中。它們存在於 schema 裡,不在 hot path 上。如果你要調校檢索品質,改這兩個值不會影響結果 — 你需要直接修改融合邏輯。
第 2 階段:Cross-Encoder 重排
Bi-encoder(生成 embedding 的模型)把 query 和文件分開編碼。快,但抓不到 query 跟特定段落之間的 token 級交互。Cross-encoder 把兩者一起通過完整的 transformer pass — 慢,但判斷相關性的準確度顯著更高。
插件把 top candidate 送到 cross-encoder API(預設 Jina Reranker v3,也支援 Voyage、SiliconFlow、Pinecone reranker),混合分數:
rerankedScore = 0.6 × crossEncoderScore + 0.4 × fusedScore
40% 錨定原始融合分數是一個保險機制。Cross-encoder 偶爾會對沾邊的內容給出高相關性。混合防止單次 reranker 幻覺主導最終排名。如果 reranker API 失敗或超時(5 秒限制),插件回退到 cosine similarity 重排 — 品質下降但不會壞掉。
第 3–6 階段:分數調整
四個乘法式的 pass 調整重排後的分數:
| 階段 | 公式 | 目的 |
|---|---|---|
| 新近度加成 | exp(-ageDays / 14) × 0.10 | 加法式加成,偏好近期記憶。14 天半衰期。 |
| 重要度 | score × (0.7 + 0.3 × importance) | 0–1 浮點數,儲存時設定。0.7× 下限確保低重要度條目不會被埋沒。 |
| 長度正規化 | score / (1 + 0.5 × log₂(max(len/500, 1))) | 懲罰意外匹配更多詞的冗長條目。500 字元以下不受影響。 |
| 時間衰減 | score × (0.5 + 0.5 × exp(-ageDays / 60)) | 長期遺忘曲線。60 天半衰期,0.5× 下限 — 不會完全消失。 |
新近度加成和時間衰減看起來相似但功能不同。新近度是短期推動(14 天半衰期,小幅加法權重),讓昨天的 debug session 排在上個月之前。時間衰減是長期信號(60 天半衰期,乘法式),逐漸降低幾個月沒被 recall 的記憶優先權。兩者並用讓系統在短期內積極偏好新鮮度,又不會永久埋沒舊知識。
第 7 階段:噪聲下限 + 多樣性過濾
兩道最終處理。首先,低於 0.35 的分數直接丟棄 — 硬噪聲下限,防止勉強相關的結果佔用有限的 context 名額。
接著一個受 Maximal Marginal Relevance 啟發的多樣性過濾器去除近似重複。如果兩筆結果的 cosine similarity > 0.85,分數較低的被降級。這不是經典的迭代式 lambda 加權 MMR 演算法 — 是更簡單的閾值檢查。但對 agent 記憶來說,你可能有十個同一條 daily note 的微調版本,它很有效。目標是防止 top-3 結果全是同個事實的三種改寫。
// 多樣性過濾(MMR 啟發)
for (const candidate of sorted) {
const tooSimilar = selected.some(
s => cosineSim(s.embedding, candidate.embedding) > 0.85
);
if (!tooSimilar) selected.push(candidate);
}多 Scope 隔離
多 agent 設定需要邊界。Code review agent 不應該讀到 DevOps agent 的基礎設施 credential。但你也不想完全隔離 — coding standard 和團隊慣例應該所有人都能存取。
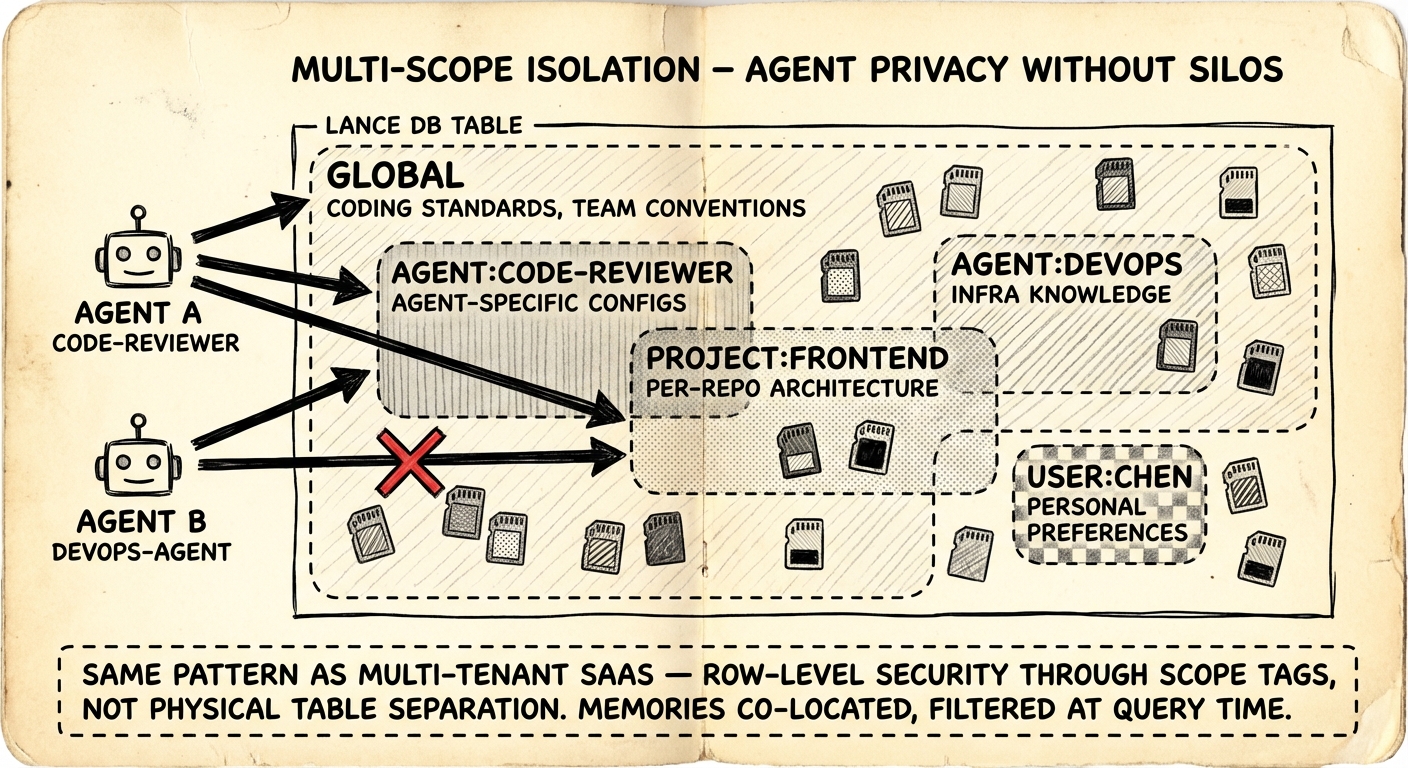
插件為每條記憶加上 scope 標籤,查詢時過濾。五種 scope:
| Scope | 可見性 | 範例 |
|---|---|---|
global | 所有 agent | Coding standard、團隊慣例 |
agent:<id> | 單一 agent | Agent 專屬設定、學到的偏好 |
project:<id> | 專案邊界 | 各 repo 的架構決策 |
user:<id> | 使用者級 | 個人工作流偏好 |
custom:<name> | 任意分組 | custom:debugging-tips、custom:oncall-runbook |
每個 agent 預設看到 global 加自己的 agent:<id> scope。透過設定擴大存取:
{
"scopes": {
"default": "global",
"agentAccess": {
"code-reviewer": ["global", "agent:code-reviewer", "project:frontend"],
"devops-agent": ["global", "agent:devops-agent", "project:infra"]
}
}
}這是在共享索引上用標籤做 row-level security — 跟每個 multi-tenant SaaS 資料庫一樣的模式。所有記憶都在同一張 LanceDB table 裡,不做物理分離,查詢時過濾處理存取控制。Trade-off 是 scope filter 帶來的微量查詢開銷,但對 agent 記憶的量級(幾百到幾千筆)來說可以忽略。
替代方案 — 每個 agent 一個獨立的向量庫 — 完全阻絕知識共享,而且維運開銷隨 agent 數量線性成長。在共享索引上做 tag-based filtering 是正確的選擇。
噪聲過濾與自適應檢索
Agent 記憶最難的部分不是儲存或檢索,是決定什麼不該存、什麼時候不該搜。
什麼會被拒絕
Auto-capture 系統用 regex 過濾會污染檢索的內容:
- Agent 拒絕回答:「我沒有相關資訊」— 存下來代表未來查缺失知識時會匹配到拒絕回應,而不是找到真正的答案
- Meta 問題:「你記得我們討論過什麼嗎?」— 關於記憶的 meta query 不應該變成記憶本身
- Keepalive 和問候:「HEARTBEAT」、「Hi」、「Hello」— 會匹配每個未來的問候,浪費 context 注入名額
- 確認噪聲:「OK」、「收到」、「謝謝」— 零資訊量,高 false positive 率
什麼時候跳過搜尋
不是每條使用者訊息都需要記憶查詢。自適應檢索節省延遲並避免注入不相關 context:
- 短確認(英文 15 字元以下、CJK 6 字元以下)— 跳過
- 斜線命令(
/help、/status)— 跳過 - 單一 emoji — 跳過
- 包含記憶觸發關鍵字的訊息(「remember」、「previously」、「last time」、「之前」、「前回」)— 無論長度一律搜尋
function shouldRetrieve(query: string): boolean {
if (MEMORY_KEYWORDS.some(k => query.includes(k))) return true;
if (query.startsWith('/')) return false;
const threshold = isCJK(query) ? 6 : 15;
return query.length >= threshold;
}CJK 感知的閾值是個重要的小細節。中文和日文每個字元承載的語義遠多於英文。一個 6 字元的中文 query 如「之前的設定」是合理的召回請求。套用英文的 15 字元閾值會壓制它。
動手做
前置條件
- OpenClaw 已安裝並運行
- Node.js 18+
- Embedding API key(Jina AI 有免費方案 — jina.ai)
步驟 1:Clone 並安裝
cd your-workspace/
git clone https://github.com/win4r/memory-lancedb-pro.git plugins/memory-lancedb-pro
cd plugins/memory-lancedb-pro
npm install步驟 2:設定 OpenClaw
更新 openclaw.json:
{
"plugins": {
"slots": {
"memory": "memory-lancedb-pro"
},
"memory-lancedb-pro": {
"embedding": {
"apiKey": "${JINA_API_KEY}",
"model": "jina-embeddings-v5-text-small",
"baseURL": "https://api.jina.ai/v1",
"dimensions": 1024
},
"retrieval": {
"mode": "hybrid",
"rerank": "cross-encoder",
"minScore": 0.3
},
"autoCapture": true,
"autoRecall": true
}
}
}步驟 3:設定 API Key 並重啟
export JINA_API_KEY="jina_xxxxxxxxxxxxx"
openclaw gateway restart
openclaw plugins list
# 應顯示:memory-lancedb-pro (active)步驟 4:驗證
在新 session 中:
> 記住:我們的 production database 在 db-prod-east-2.example.com,port 5432
開一個新 session:
> 我們的 production database 位址是什麼?
插件應該自動 recall 儲存的事實,不需要你要求搜尋。
故障排除
- status 顯示 "memory unavailable":跑
openclaw plugins doctor— 通常是 API key 沒設 - 第一次查詢慢:LanceDB 在首次搜尋時才建立 FTS 索引。後續查詢很快。
- 沒有自動 recall:確認 config 中
autoRecall: true,然後重啟 gateway
Embedding Provider 的取捨
插件用 OpenAI SDK 搭配可設定的 baseURL,所以任何 OpenAI 相容的 embedding API 都能用。選擇取決於延遲、成本、以及你能不能接受外部 API 呼叫。
| Provider | Model | 維度 | 備註 |
|---|---|---|---|
| Jina | jina-embeddings-v5-text-small | 1024 | 有免費方案,~50ms 延遲。支援非對稱 task-aware embedding(taskQuery vs taskPassage)。 |
| OpenAI | text-embedding-3-small | 1536 | $0.02/1M tokens。經過實戰驗證,生態系支援最廣。 |
| gemini-embedding-001 | 3072 | 有免費方案。最高維度 — 對對話記憶來說 overkill,對程式碼搜尋可能有用。 | |
| Ollama | nomic-embed-text | 768 | 完全本地,零 API 呼叫。最適合隔離環境或注重隱私的場景。 |
對 agent 記憶來說,1024 維已經很充裕。對話文字相比程式碼搜尋或學術論文,詞彙量有限。更高維度捕捉更多語義細微差異,但成本更高。對幾千筆 agent 記憶的資料庫,成本差異微乎其微 — 但本地 Ollama 模型(~20ms)和遠端 API 呼叫(~80ms)之間的延遲差異,在每條使用者訊息都觸發檢索時會累積。
Jina 的 task-aware embedding 值得一提。大多數 embedding 教學把 query 和 passage 用同樣方式編碼。Jina 的 taskQuery 和 taskPassage 參數做非對稱優化 — query embedding 針對 recall 調校,passage embedding 針對 precision。是一個容易被忽略但可測量的準確度提升。
限制與誠實的 Trade-off
這個插件不是沒有妥協。
Reranking 依賴外部 API。 Cross-encoder reranking 每次檢索都要呼叫外部 API,增加延遲(每次查詢 ~200-500ms)和一個故障點。回退到 cosine similarity reranking 是優雅的降級,但你會失去準確度提升。如果在限制外部 API 呼叫的環境中運行,你需要停用 reranking 或自行架設模型。
沒有內建 embedding 模型。 不像 OpenClaw 的內建記憶(可以自動選擇本地 embedding provider),這個插件要求你明確設定 embedding provider。更多控制但更多設定。
記憶捕獲仍然是 LLM 驅動的。 插件替換了檢索和儲存,但記憶捕獲仍然依賴 agent 決定要存什麼。autoCapture 功能透過在系統層級攔截訊息來幫忙,但根本限制 — model 不知道自己不知道什麼 — 仍然存在。
單一 table 設計的規模限制。 所有 scope 的所有記憶都在一張 LanceDB table 裡,靠查詢時的 scope 過濾。對幾百個 agent 配幾百萬筆記憶,這可能成為瓶頸。對典型用例(幾個 agent、幾千筆記憶),完全沒問題。
重點整理
OpenClaw 的內建記憶為簡潔而設計 — 純檔案、最少基礎設施、日常使用夠用。memory-lancedb-pro 插件為可靠性而設計 — 結構化檢索、scope 隔離、自動噪聲拒絕。兩者的差距就是「agent 偶爾記得」和「agent 穩定地 recall 重要的東西」之間的距離。
檢索 pipeline 是整個 codebase 最有趣的部分。每個階段針對 naive 向量搜尋的特定失敗模式,而設計選擇(乘法式 BM25 加成而非傳統加權融合、雙時間衰減曲線、硬噪聲下限)反映的是實際實驗而非教科書公式。如果你在建任何 RAG 系統,原始碼值得一讀 — 特別是 retriever.ts 和 noise-filter.ts。