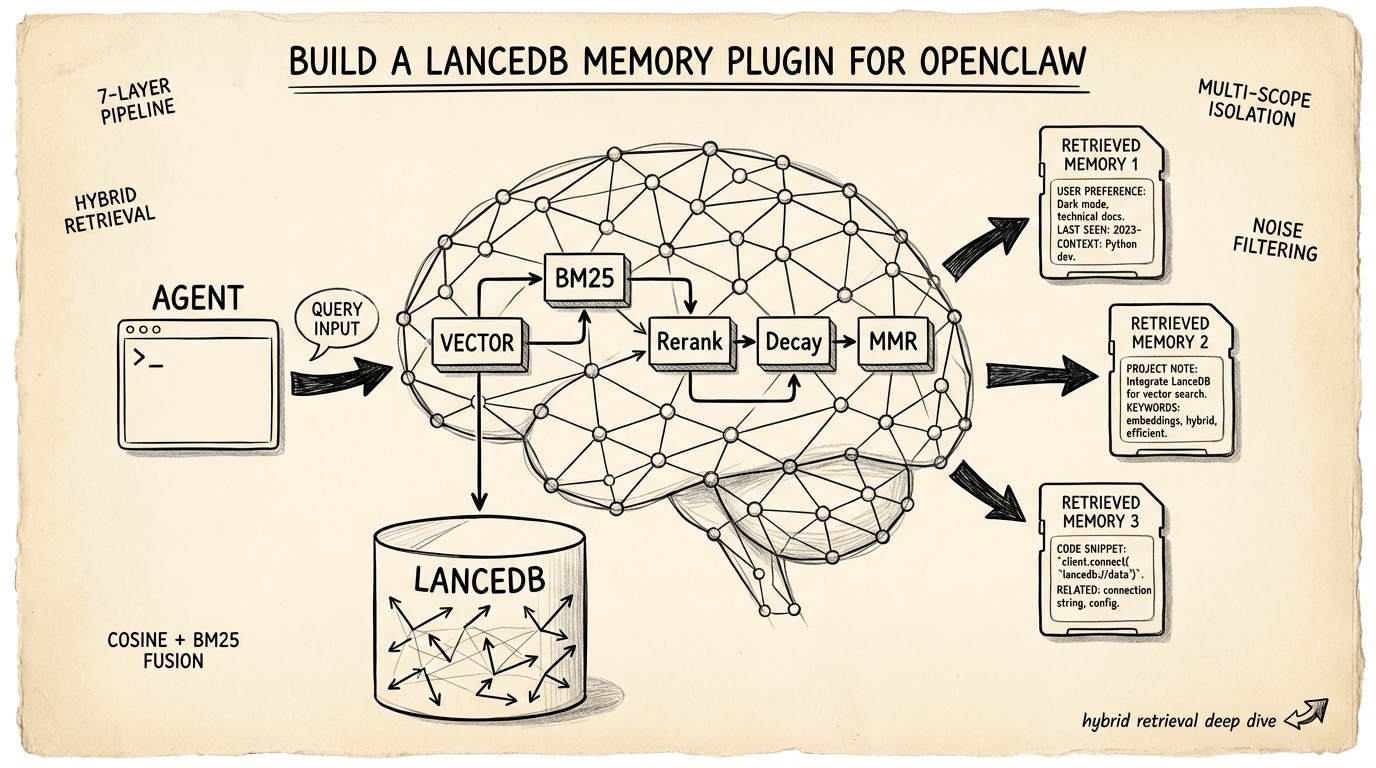
为 OpenClaw 打造 LanceDB 记忆插件
OpenClaw 内置记忆不够可靠?用 LanceDB 打造混合检索、多 scope 隔离、噪声过滤的记忆插件。
我花了一个小时带 OpenClaw agent 走过一整套部署环境 — VPN tunnel、非标准 port、auth/middleware.ts 里那个只在高负载才会浮现的 race condition。下一次 session,全部消失。Agent 完全不记得这些事。
OpenClaw 用 Markdown 文件来存记忆。在一定程度内能用,但超过就不行了。Model 自己决定什么值得存,这意味着它会固定漏掉你觉得重要但它没意识到的细节。社区开发的 memory-lancedb-pro 插件把整个记忆子系统换掉 — 用向量数据库搭配混合检索、scope 访问控制和自动噪声过滤取代平面文件。我在日常工作流中跑了一段时间。这篇文章拆解它内部的工程设计、代码实际在做什么(我读过了),以及设计上真正的 trade-off。
OpenClaw 记忆系统的瓶颈在哪
OpenClaw 默认的记忆把信息存在两个地方:MEMORY.md 放策展过的长期知识,memory/YYYY-MM-DD.md 放每日 session log。都是纯 Markdown。底层的记忆插件把这些文件索引到每个 agent 专属的 SQLite 数据库(约 400 token chunk,80 token overlap),并通过 memory_search 支持搜索 — 包含向量相似度和 BM25 关键字匹配。
所以检索引擎本身不是问题。问题出在周围的一切。
Agent 控制什么被保存。 记忆捕获是 LLM 驱动的 — model 自己决定什么值得写入 MEMORY.md。实际上它会固定漏掉微妙的细节:随口提到的 port number、描述过一次的 workaround、某个 env var 的名称。这些细节很重要。Model 不知道它们重要。
Context compaction 侵蚀已注入的记忆。 当对话接近 context window 上限,OpenClaw 会压缩旧消息。磁盘上的记忆文件不受影响 — 但先前检索并注入对话的 context 会在压缩过程中被摘要或丢弃。下次 agent 需要那个事实时,它必须重新检索,前提是它知道要去找。有个 memoryFlush 机制可以在压缩前触发写入,但不是完整的解决方案。
召回是 opt-in 的。 memory_search 只在 agent 自己决定调用时才会触发。没有自动检索意味着相关事实安静地躺在索引里,agent 却用不完整的信息自信地工作。你可以用 system prompt 指示 agent 更积极地搜索记忆,但你仍然依赖 model 去稳定地遵守指令。
这些不是 bug,是为了简洁和低资源消耗做的架构选择。对单 agent、偶尔遗忘可以忍受的场景,内置系统够用。但当你需要可靠的跨 session recall — 跑多 agent pipeline、或你的 agent 处理的基础设施中一个忘记的 credential 路径就意味着凌晨三点被 page — 你需要更结构化的方案。
为什么选 LanceDB
在深入检索 pipeline 之前,值得问:为什么偏偏是 LanceDB?
LanceDB 是一个嵌入式、serverless 的向量数据库,构建在 Lance 列式格式(基于 Apache Arrow)之上。它在 process 内运行 — 不需要独立 server、不需要 Docker container、不需要 managed service。把它想成向量版的 SQLite。它从磁盘 memory-map 文件并用 SIMD 优化查询,处理 2 亿以上的向量,原生支持 ANN 向量搜索和 BM25 全文搜索。
对 agent 记忆来说,嵌入式架构几乎是完美契合。Agent 记忆数据库通常很小 — 几千到几万条。你不需要 Qdrant 的分布式集群或 Pinecone 的托管基础设施。你需要的是瞬间启动、零运维、跟 agent process 共存的东西。LanceDB 恰好如此,而且它原生的混合搜索意味着你不需要另外接一个全文引擎。
主要限制:LanceDB 的全文搜索不支持布尔运算符(AND、OR),生态也比 Qdrant 或 Chroma 年轻。对 agent 记忆的工作负载来说,两者都不是问题。
混合检索 Pipeline
纯向量搜索处理语义相似度很好 — 它知道"跑 gateway 的那台机器"跟"gateway host"是同个意思。但对精确匹配就不行。Error code、IP 地址、函数名称、config key — 这些没有有意义的语义邻居,需要关键字匹配。
memory-lancedb-pro 插件跑一个多阶段检索 pipeline,融合向量和关键字信号,再通过一系列后处理来压制噪声和过时结果。以下是代码实际在做的事。
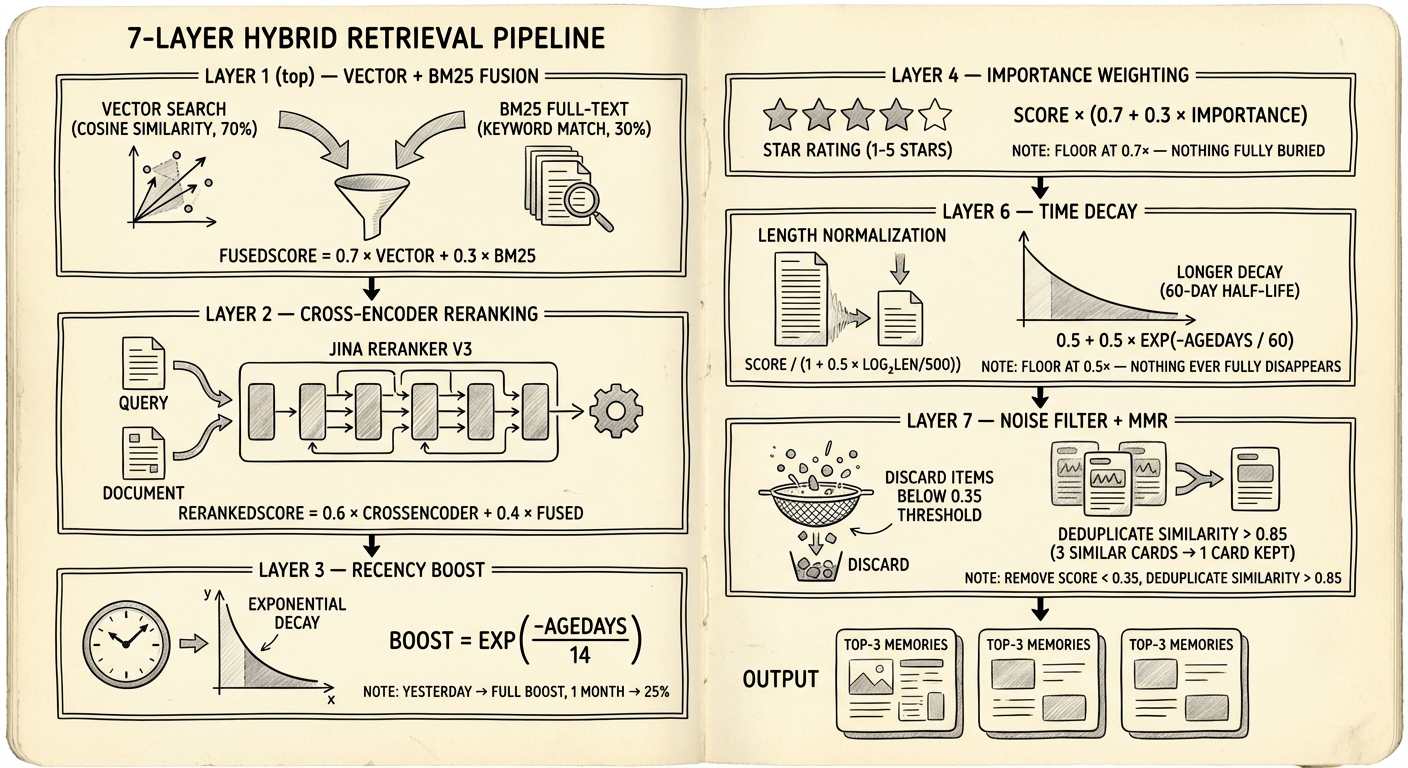
第 1 阶段:向量 + BM25 融合
每个 query 通过 Promise.all() 同时跑向量搜索(LanceDB ANN 的 cosine similarity)和 BM25 全文搜索。融合方式不是大多数 RAG 教程里那种传统加权和。读 retriever.ts 的实际代码,插件用的是乘法式的 BM25 加成:
fusedScore = vectorScore + (bm25Hit ? 0.15 × vectorScore : 0)
如果一条结果同时出现在向量和 BM25 结果中,会得到 15% 的分数加成。如果只出现在 BM25(没有向量匹配),直接用原始 BM25 分数。这跟经典的 α × vector + (1-α) × bm25 公式不同 — 插件的 README 描述为"超越传统 RRF 的调校"。
值得注意:config 暴露了 vectorWeight 和 bm25Weight 参数(默认 0.7/0.3),但这些实际上没被用在融合计算中。它们存在于 schema 里,不在 hot path 上。如果你要调校检索质量,改这两个值不会影响结果 — 你需要直接修改融合逻辑。
第 2 阶段:Cross-Encoder 重排
Bi-encoder(生成 embedding 的模型)把 query 和文档分开编码。快,但抓不到 query 跟特定段落之间的 token 级交互。Cross-encoder 把两者一起通过完整的 transformer pass — 慢,但判断相关性的准确度显著更高。
插件把 top candidate 送到 cross-encoder API(默认 Jina Reranker v3,也支持 Voyage、SiliconFlow、Pinecone reranker),混合分数:
rerankedScore = 0.6 × crossEncoderScore + 0.4 × fusedScore
40% 锚定原始融合分数是一个保险机制。Cross-encoder 偶尔会对沾边的内容给出高相关性。混合防止单次 reranker 幻觉主导最终排名。如果 reranker API 失败或超时(5 秒限制),插件回退到 cosine similarity 重排 — 质量下降但不会坏掉。
第 3–6 阶段:分数调整
四个乘法式的 pass 调整重排后的分数:
| 阶段 | 公式 | 目的 |
|---|---|---|
| 新近度加成 | exp(-ageDays / 14) × 0.10 | 加法式加成,偏好近期记忆。14 天半衰期。 |
| 重要度 | score × (0.7 + 0.3 × importance) | 0–1 浮点数,存储时设定。0.7× 下限确保低重要度条目不会被埋没。 |
| 长度正则化 | score / (1 + 0.5 × log₂(max(len/500, 1))) | 惩罚意外匹配更多词的冗长条目。500 字符以下不受影响。 |
| 时间衰减 | score × (0.5 + 0.5 × exp(-ageDays / 60)) | 长期遗忘曲线。60 天半衰期,0.5× 下限 — 不会完全消失。 |
新近度加成和时间衰减看起来相似但功能不同。新近度是短期推动(14 天半衰期,小幅加法权重),让昨天的 debug session 排在上个月之前。时间衰减是长期信号(60 天半衰期,乘法式),逐渐降低几个月没被 recall 的记忆优先权。两者并用让系统在短期内积极偏好新鲜度,又不会永久埋没旧知识。
第 7 阶段:噪声下限 + 多样性过滤
两道最终处理。首先,低于 0.35 的分数直接丢弃 — 硬噪声下限,防止勉强相关的结果占用有限的 context 名额。
接着一个受 Maximal Marginal Relevance 启发的多样性过滤器去除近似重复。如果两条结果的 cosine similarity > 0.85,分数较低的被降级。这不是经典的迭代式 lambda 加权 MMR 算法 — 是更简单的阈值检查。但对 agent 记忆来说,你可能有十个同一条 daily note 的微调版本,它很有效。目标是防止 top-3 结果全是同个事实的三种改写。
// 多样性过滤(MMR 启发)
for (const candidate of sorted) {
const tooSimilar = selected.some(
s => cosineSim(s.embedding, candidate.embedding) > 0.85
);
if (!tooSimilar) selected.push(candidate);
}多 Scope 隔离
多 agent 设置需要边界。Code review agent 不应该读到 DevOps agent 的基础设施 credential。但你也不想完全隔离 — coding standard 和团队惯例应该所有人都能访问。
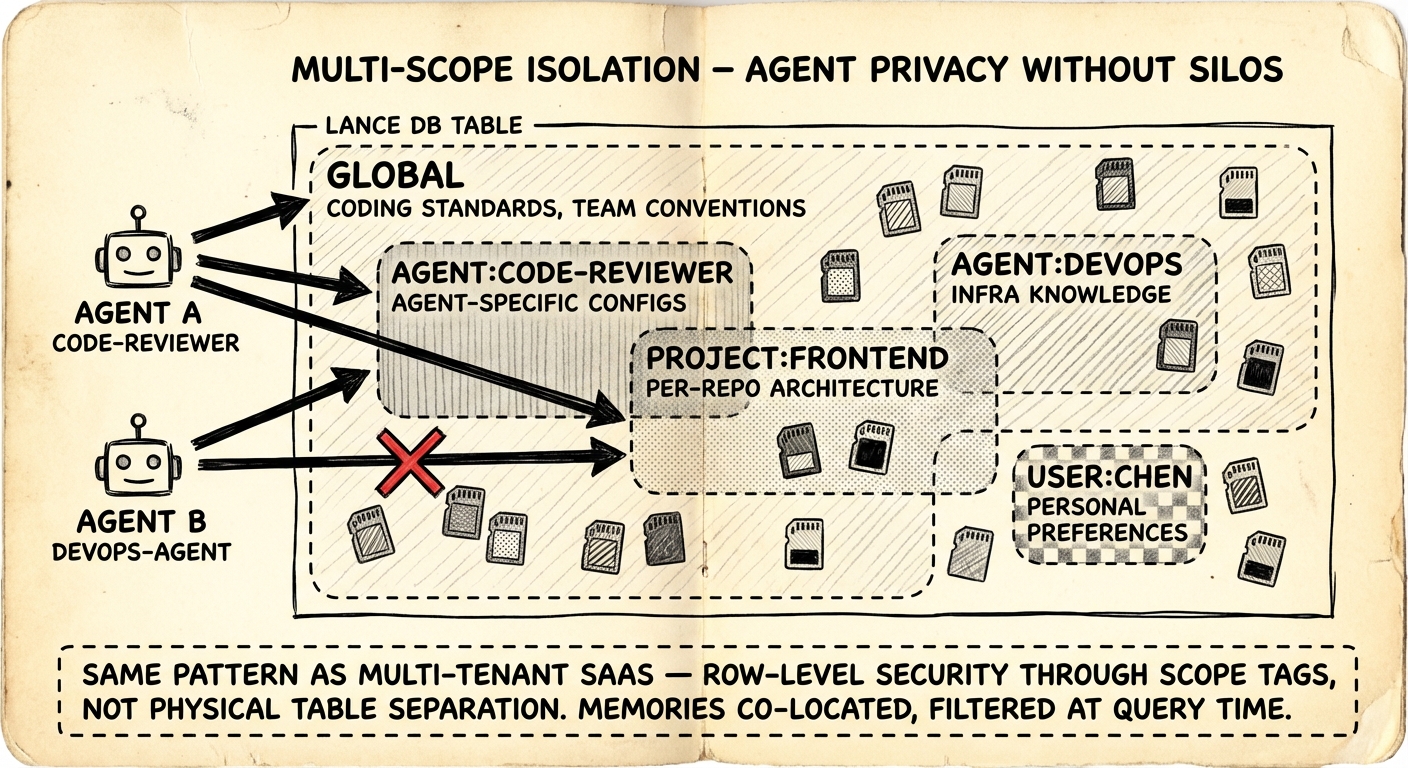
插件为每条记忆加上 scope 标签,查询时过滤。五种 scope:
| Scope | 可见性 | 示例 |
|---|---|---|
global | 所有 agent | Coding standard、团队惯例 |
agent:<id> | 单个 agent | Agent 专属配置、学到的偏好 |
project:<id> | 项目边界 | 各 repo 的架构决策 |
user:<id> | 用户级 | 个人工作流偏好 |
custom:<name> | 任意分组 | custom:debugging-tips、custom:oncall-runbook |
每个 agent 默认看到 global 加自己的 agent:<id> scope。通过配置扩大访问:
{
"scopes": {
"default": "global",
"agentAccess": {
"code-reviewer": ["global", "agent:code-reviewer", "project:frontend"],
"devops-agent": ["global", "agent:devops-agent", "project:infra"]
}
}
}这是在共享索引上用标签做 row-level security — 跟每个 multi-tenant SaaS 数据库一样的模式。所有记忆都在同一张 LanceDB table 里,不做物理分离,查询时过滤处理访问控制。Trade-off 是 scope filter 带来的微量查询开销,但对 agent 记忆的量级(几百到几千条)来说可以忽略。
替代方案 — 每个 agent 一个独立的向量库 — 完全阻绝知识共享,而且运维开销随 agent 数量线性增长。在共享索引上做 tag-based filtering 是正确的选择。
噪声过滤与自适应检索
Agent 记忆最难的部分不是存储或检索,是决定什么不该存、什么时候不该搜。
什么会被拒绝
Auto-capture 系统用 regex 过滤会污染检索的内容:
- Agent 拒绝回答:"我没有相关信息" — 存下来意味着未来查缺失知识时会匹配到拒绝回应,而不是找到真正的答案
- Meta 问题:"你记得我们讨论过什么吗?" — 关于记忆的 meta query 不应该变成记忆本身
- Keepalive 和问候:"HEARTBEAT"、"Hi"、"Hello" — 会匹配每个未来的问候,浪费 context 注入名额
- 确认噪声:"OK"、"收到"、"谢谢" — 零信息量,高 false positive 率
什么时候跳过搜索
不是每条用户消息都需要记忆查询。自适应检索节省延迟并避免注入不相关 context:
- 短确认(英文 15 字符以下、CJK 6 字符以下)— 跳过
- 斜杠命令(
/help、/status)— 跳过 - 单个 emoji — 跳过
- 包含记忆触发关键字的消息("remember"、"previously"、"last time"、"之前"、"前回")— 无论长度一律搜索
function shouldRetrieve(query: string): boolean {
if (MEMORY_KEYWORDS.some(k => query.includes(k))) return true;
if (query.startsWith('/')) return false;
const threshold = isCJK(query) ? 6 : 15;
return query.length >= threshold;
}CJK 感知的阈值是个重要的小细节。中文和日文每个字符承载的语义远多于英文。一个 6 字符的中文 query 如"之前的设定"是合理的召回请求。套用英文的 15 字符阈值会压制它。
动手做
前置条件
- OpenClaw 已安装并运行
- Node.js 18+
- Embedding API key(Jina AI 有免费方案 — jina.ai)
步骤 1:Clone 并安装
cd your-workspace/
git clone https://github.com/win4r/memory-lancedb-pro.git plugins/memory-lancedb-pro
cd plugins/memory-lancedb-pro
npm install步骤 2:配置 OpenClaw
更新 openclaw.json:
{
"plugins": {
"slots": {
"memory": "memory-lancedb-pro"
},
"memory-lancedb-pro": {
"embedding": {
"apiKey": "${JINA_API_KEY}",
"model": "jina-embeddings-v5-text-small",
"baseURL": "https://api.jina.ai/v1",
"dimensions": 1024
},
"retrieval": {
"mode": "hybrid",
"rerank": "cross-encoder",
"minScore": 0.3
},
"autoCapture": true,
"autoRecall": true
}
}
}步骤 3:设置 API Key 并重启
export JINA_API_KEY="jina_xxxxxxxxxxxxx"
openclaw gateway restart
openclaw plugins list
# 应显示:memory-lancedb-pro (active)步骤 4:验证
在新 session 中:
> 记住:我们的 production database 在 db-prod-east-2.example.com,port 5432
开一个新 session:
> 我们的 production database 地址是什么?
插件应该自动 recall 存储的事实,不需要你要求搜索。
故障排除
- status 显示 "memory unavailable":跑
openclaw plugins doctor— 通常是 API key 没设 - 第一次查询慢:LanceDB 在首次搜索时才建立 FTS 索引。后续查询很快。
- 没有自动 recall:确认 config 中
autoRecall: true,然后重启 gateway
Embedding Provider 的取舍
插件用 OpenAI SDK 搭配可配置的 baseURL,所以任何 OpenAI 兼容的 embedding API 都能用。选择取决于延迟、成本、以及你能不能接受外部 API 调用。
| Provider | Model | 维度 | 备注 |
|---|---|---|---|
| Jina | jina-embeddings-v5-text-small | 1024 | 有免费方案,~50ms 延迟。支持非对称 task-aware embedding(taskQuery vs taskPassage)。 |
| OpenAI | text-embedding-3-small | 1536 | $0.02/1M tokens。经过实战验证,生态支持最广。 |
| gemini-embedding-001 | 3072 | 有免费方案。最高维度 — 对对话记忆来说 overkill,对代码搜索可能有用。 | |
| Ollama | nomic-embed-text | 768 | 完全本地,零 API 调用。最适合隔离环境或注重隐私的场景。 |
对 agent 记忆来说,1024 维已经很充裕。对话文字相比代码搜索或学术论文,词汇量有限。更高维度捕捉更多语义细微差异,但成本更高。对几千条 agent 记忆的数据库,成本差异微乎其微 — 但本地 Ollama 模型(~20ms)和远端 API 调用(~80ms)之间的延迟差异,在每条用户消息都触发检索时会累积。
Jina 的 task-aware embedding 值得一提。大多数 embedding 教程把 query 和 passage 用同样方式编码。Jina 的 taskQuery 和 taskPassage 参数做非对称优化 — query embedding 针对 recall 调校,passage embedding 针对 precision。是一个容易被忽略但可测量的准确度提升。
限制与诚实的 Trade-off
这个插件不是没有妥协。
Reranking 依赖外部 API。 Cross-encoder reranking 每次检索都要调用外部 API,增加延迟(每次查询 ~200-500ms)和一个故障点。回退到 cosine similarity reranking 是优雅的降级,但你会失去准确度提升。如果在限制外部 API 调用的环境中运行,你需要停用 reranking 或自行部署模型。
没有内置 embedding 模型。 不像 OpenClaw 的内置记忆(可以自动选择本地 embedding provider),这个插件要求你明确配置 embedding provider。更多控制但更多配置。
记忆捕获仍然是 LLM 驱动的。 插件替换了检索和存储,但记忆捕获仍然依赖 agent 决定要存什么。autoCapture 功能通过在系统层级拦截消息来帮忙,但根本限制 — model 不知道自己不知道什么 — 仍然存在。
单一 table 设计的规模限制。 所有 scope 的所有记忆都在一张 LanceDB table 里,靠查询时的 scope 过滤。对几百个 agent 配几百万条记忆,这可能成为瓶颈。对典型用例(几个 agent、几千条记忆),完全没问题。
重点总结
OpenClaw 的内置记忆为简洁而设计 — 纯文件、最少基础设施、日常使用够用。memory-lancedb-pro 插件为可靠性而设计 — 结构化检索、scope 隔离、自动噪声拒绝。两者的差距就是"agent 偶尔记得"和"agent 稳定地 recall 重要的东西"之间的距离。
检索 pipeline 是整个 codebase 最有趣的部分。每个阶段针对 naive 向量搜索的特定失败模式,而设计选择(乘法式 BM25 加成而非传统加权融合、双时间衰减曲线、硬噪声下限)反映的是实际实验而非教科书公式。如果你在建任何 RAG 系统,源码值得一读 — 特别是 retriever.ts 和 noise-filter.ts。