深度解析:Claude Code Remote Control 的底层工作原理
逆向分析 Claude Code /remote-control 背后的 relay 协议、心跳机制、断线重连与安全模型。
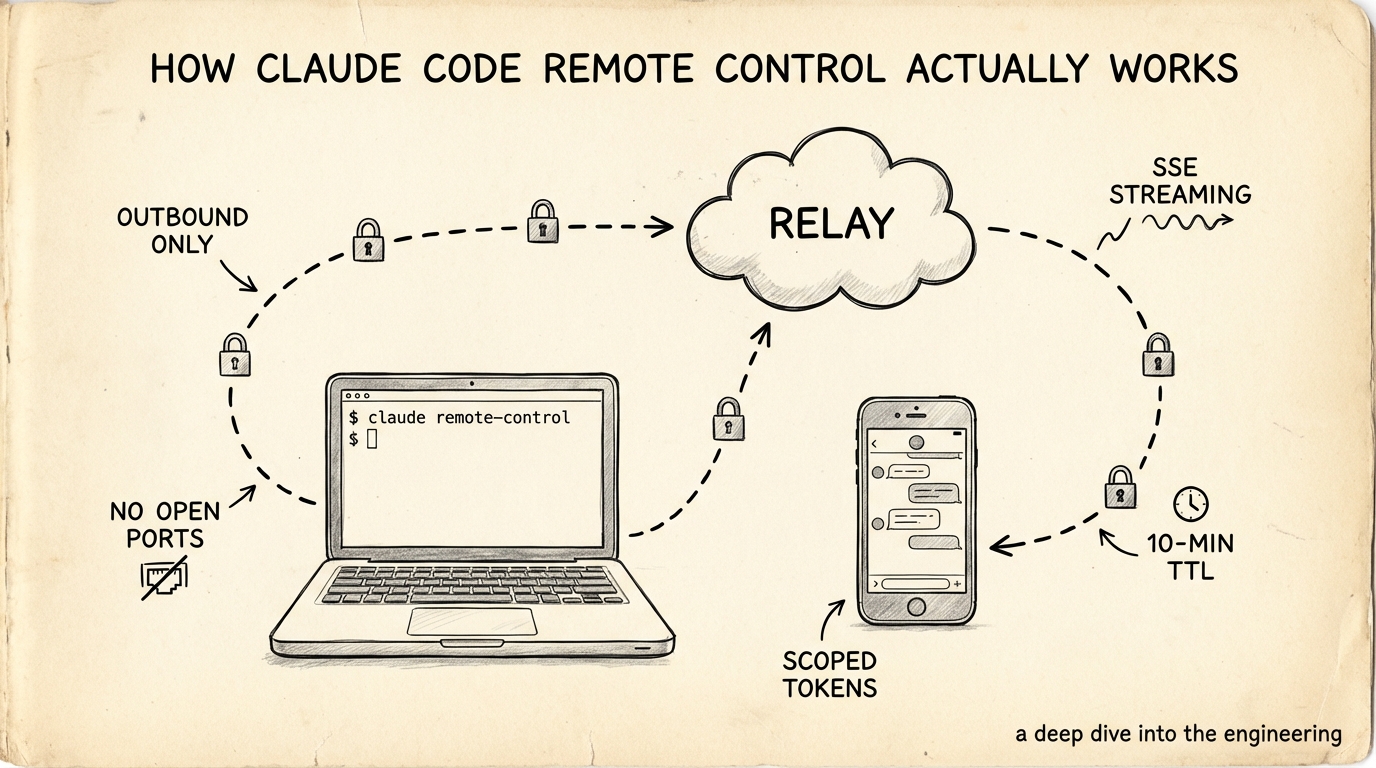
这不应该能跑通
两天前,Anthropic 上线了一个功能:在笔记本电脑上启动一个 Claude Code 会话,然后用手机直接接入。不需要 SSH,不需要端口转发。扫个二维码就连上了。
我的第一反应是"挺酷"。第二反应是"等等 - 怎么做到的?"
你的笔记本在 NAT 后面。手机走的是 LTE。没有共享网络,没有 VPN。然而你在 iPhone 上输入的指令,却能在家里桌上的 MacBook 上触发 git diff。
我花了两天时间翻阅官方文档、GitHub issues、bug 报告、第三方安全审计和 Hacker News 讨论帖,把这个东西拆了个底朝天。以下是我的发现。
连接架构
零入站端口
整个设计建立在一个约束之上:你的机器绝不开放任何监听端口。一个都没有。官方文档说得很直白:
"Your local Claude Code session makes outbound HTTPS requests only and never opens inbound ports on your machine."
如果你用过 Tailscale,对这个套路应该不陌生。Tailscale 的 DERP relay 服务端原理相同 - 两个端点都向 relay 发起出站连接,由 relay 将它们缝合在一起。Claude Code 做的事情一模一样,只不过它转发的是应用层消息而非网络数据包。
Relay 就在 Anthropic API 内部
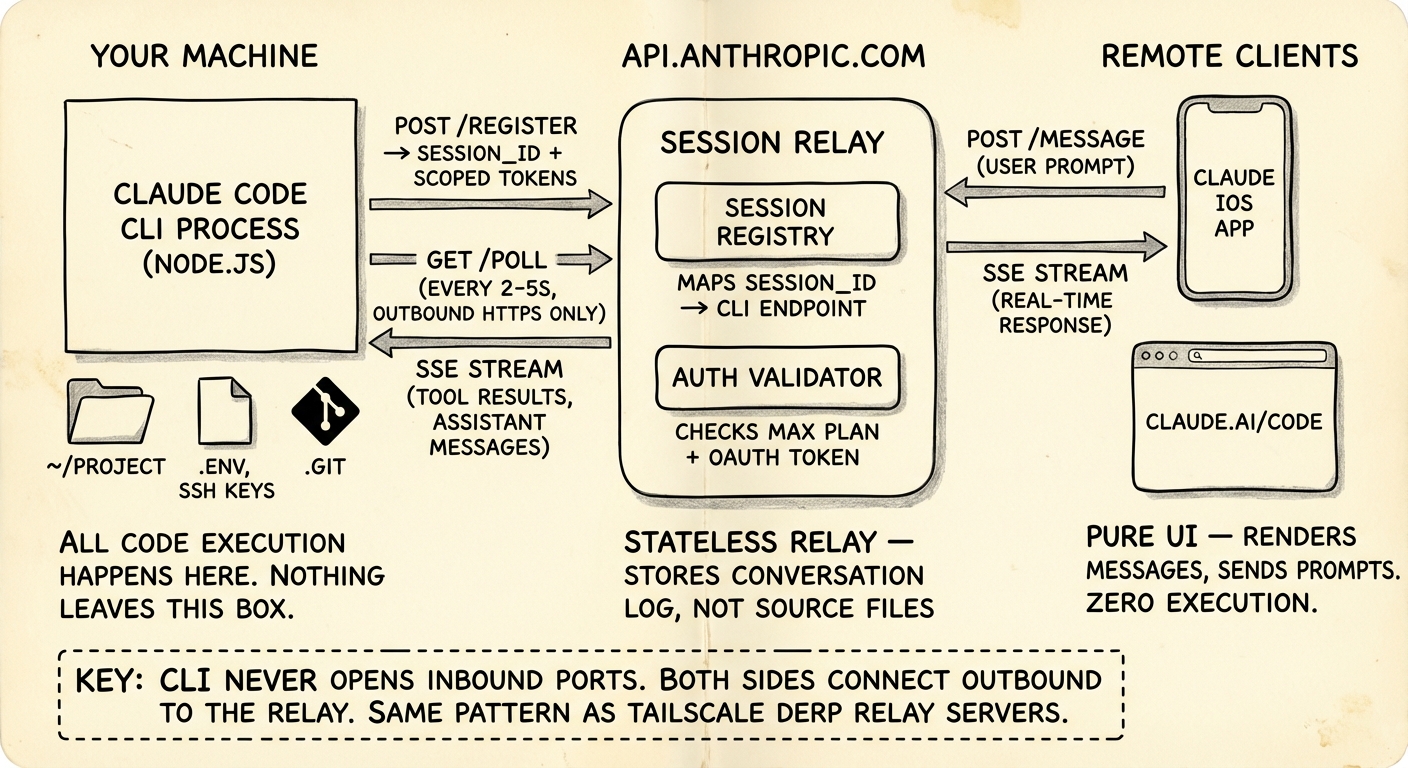
三个角色:
你的机器 - Claude Code CLI 进程。拥有你的文件系统、SSH 密钥、.env、git 仓库的完整访问权限。所有代码执行都发生在这里,不在其他任何地方。
api.anthropic.com - 充当消息 relay 和会话路由。它在端点之间转发聊天消息和工具执行结果。它不存储你的源代码。只有对话消息经过这里。
手机 / 浏览器 - claude.ai/code 或 Claude 移动端应用。纯 UI。渲染对话、发送 prompt。不在这里执行任何代码。
协议
根据文档描述和 bug 报告拼凑出的协议细节:
- CLI -> Anthropic:HTTPS polling。CLI 每隔几秒询问一次"有没有新消息?"
- Anthropic -> CLI:SSE (Server-Sent Events) 将工具执行结果和助手消息流式推回 - 与标准 Claude API streaming 使用的机制相同。
- 手机 -> Anthropic:标准 HTTPS + SSE,与
claude.ai聊天界面一致。
这个 relay 不是网络隧道。它不转发 TCP 数据包。它转发的是结构化的应用层消息 - 聊天 prompt、工具执行结果、状态更新。这与 ngrok 或 VS Code Remote Tunnels 完全不同,后者转发的是原始网络流量。
这也意味着 remote control 无法暴露任意端口或服务。它被限定在 Claude Code 的对话模型内。这不是缺陷 - 而是比通用隧道小得多的攻击面。
会话生命周期
大多数人在已有会话内启动 remote control:
# 在运行中的会话内启动 remote control
/remote-control
# 简写
/rc
# 或者直接从 CLI 启动一个新会话
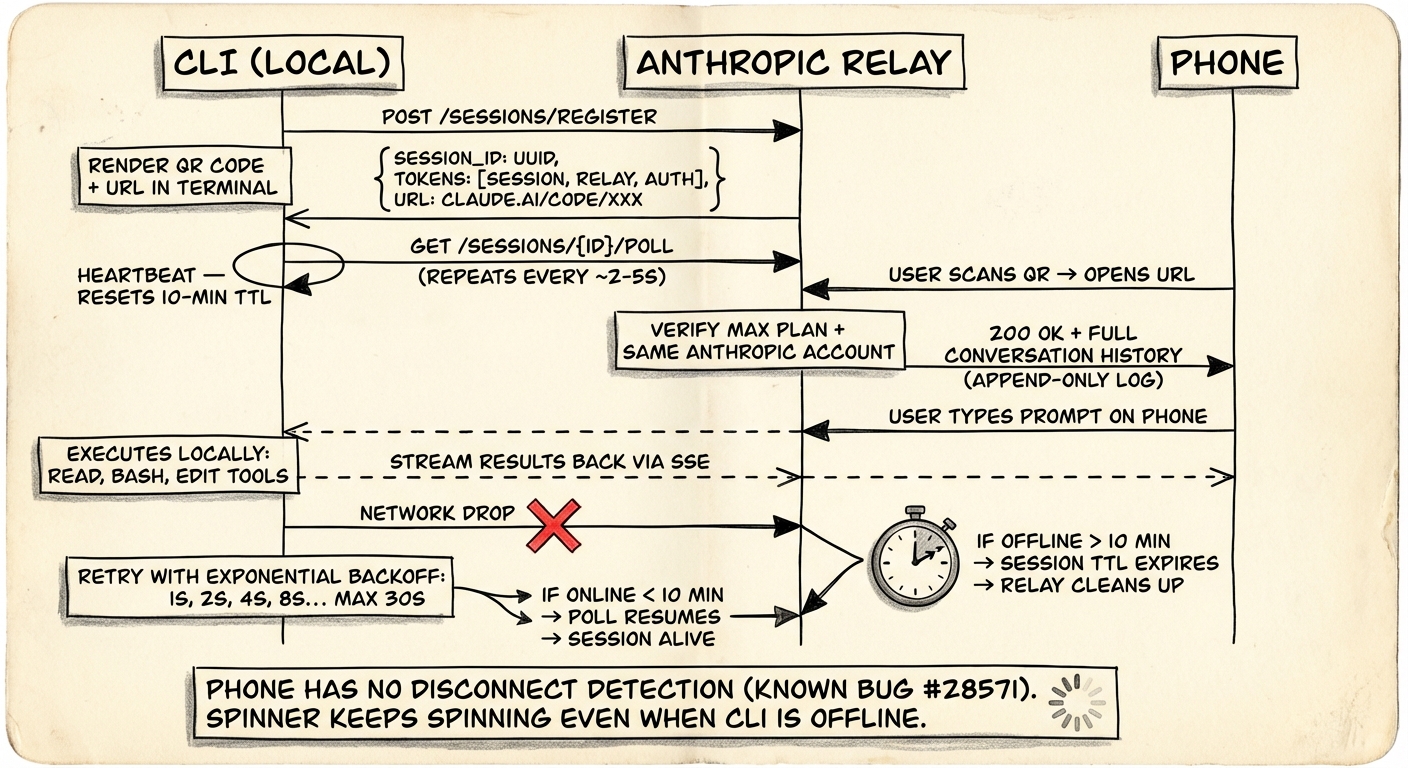
claude remote-control第一步:注册
CLI 向 Anthropic API 发送 HTTPS POST 请求来注册会话。API 返回:
- 一个 session ID - UUID 格式
- 一个 session URL - 在
claude.ai/code下,指向这个特定会话 - 多个短期凭证 - 每个凭证的作用域限定为单一用途
第二步:二维码
终端显示:
- 一个可点击的 session URL
- 一个二维码(按空格键切换显示)
没有配对协议。没有蓝牙握手。没有设备认证。扫码即连接。这种简洁性既是设计的最大优点,也是最大隐患 - 安全性部分会详细讨论。
第三步:Poll 循环
CLI 进入轮询循环:
while session_alive:
response = HTTPS_GET("/sessions/{id}/poll", session_token)
if response.has_new_message:
execute_locally(response.message)
stream_results_back()
wait(poll_interval) # 大约 2-5 秒
具体的 polling 间隔没有公开文档记载。根据实际使用体验 - 远程命令几乎瞬间到达,偶尔有轻微延迟 - 我估计在 2-5 秒之间。很可能是自适应的:活跃对话时缩短间隔,空闲时拉长。
第四步:手机连接
扫描二维码后:
- Claude 应用打开 session URL
- Anthropic 验证你的账户是否为 Max plan
- 会话出现在你的会话列表中,带有绿色指示点
- 完整对话历史同步到手机
从此刻起是双向通信。手机输入 -> relay -> CLI 本地执行 -> 结果通过 relay 流回 -> 手机渲染。从终端发起也是同样的流程。两端保持同步。
心跳问题
这才是有意思的地方 - 也是当前实现暴露裂缝的地方。
10 分钟硬超时
如果你的机器断网约 10 分钟,会话就死了。CLI 进程退出。你得重新执行 /rc。
这指向服务端的 session TTL。Relay 为每个会话维护一个计时器。每次成功的 poll 都会重置它。超过 10 分钟的阈值,relay 就宣告会话死亡并清理资源。
睡眠存活
合上笔记本盖子,会话依然存活 - 前提是睡眠时间不超过超时阈值。机器唤醒后,CLI 恢复 polling,计时器重置,一切恢复正常。不需要任何特殊的睡眠检测逻辑。Poll 循环天然就能处理这种情况。
手机完全不知道你已离线
问题在这里。当 CLI 离线时,手机毫不知情。
"When the connection drops, there is no indication on the iOS app that the connection is lost. The session still appears 'Interactive' on iOS even after disconnection. Messages silently fail."
加载动画继续转。UI 看起来一切正常。你输入消息,看起来像是发出去了,但实际上石沉大海。
这说明心跳是单向的。CLI 通过 polling 向 relay 证明自己还活着,但 relay 不会将健康状态推送给远程客户端。手机无法区分"服务端宕了"和"我只是暂时没收到回复"。
教科书级的分布式系统问题。
我的修复方案
如果让我来设计:
- 服务端:relay 为每个会话发布一个
last_seen时间戳,每次 CLI 成功 poll 时更新 - 客户端:手机订阅
last_seen。如果now - last_seen > 15s,显示黄色"连接可能不稳定"警告。超过 60 秒,显示红色"连接已断开" - 乐观投递:断线期间输入的消息在客户端本地排队,带有"待发送"标记。CLI 恢复后投递。超过 10 分钟则标记为"投递失败"
与 WhatsApp 的消息投递状态完全同理 - 一个勾表示已发送到服务端,两个勾表示已投递到设备,蓝色勾表示已读。
断线重连
网络中断,CLI 不会立刻放弃。
已知信息
- 机器恢复网络后,会话自动重连
- 持续断线超过约 10 分钟,会话超时
- 超时后需要重新执行
/rc。旧的对话可以通过--resume访问,但远程链接已断开
退避策略
几乎可以确定是指数退避 - 这是 HTTP polling 重试的行业标准做法,且与观察到的行为吻合:
retry_interval = min(1s * 2^attempt, 30s)
// 1s, 2s, 4s, 8s, 16s, 30s, 30s, 30s...
// 在 10 分钟超时前大约能重试 20 次
手机端重连是坏的
CLI 端重连没问题。手机端不行。来自 GitHub issue #28402:
"Navigating away from the session on mobile loses the connection permanently. The original session URL doesn't reconnect — it opens a new unlinked thread."
强制退出应用再重新打开 - 你会看到过时的对话状态,可能是几小时前的。唯一的选项是"新建会话",这意味着丢失所有上下文。
这是一个客户端状态管理的 bug。应用显然没有在本地持久化 session 绑定关系,因此重启后找不到回到 relay session 的路径。
安全模型
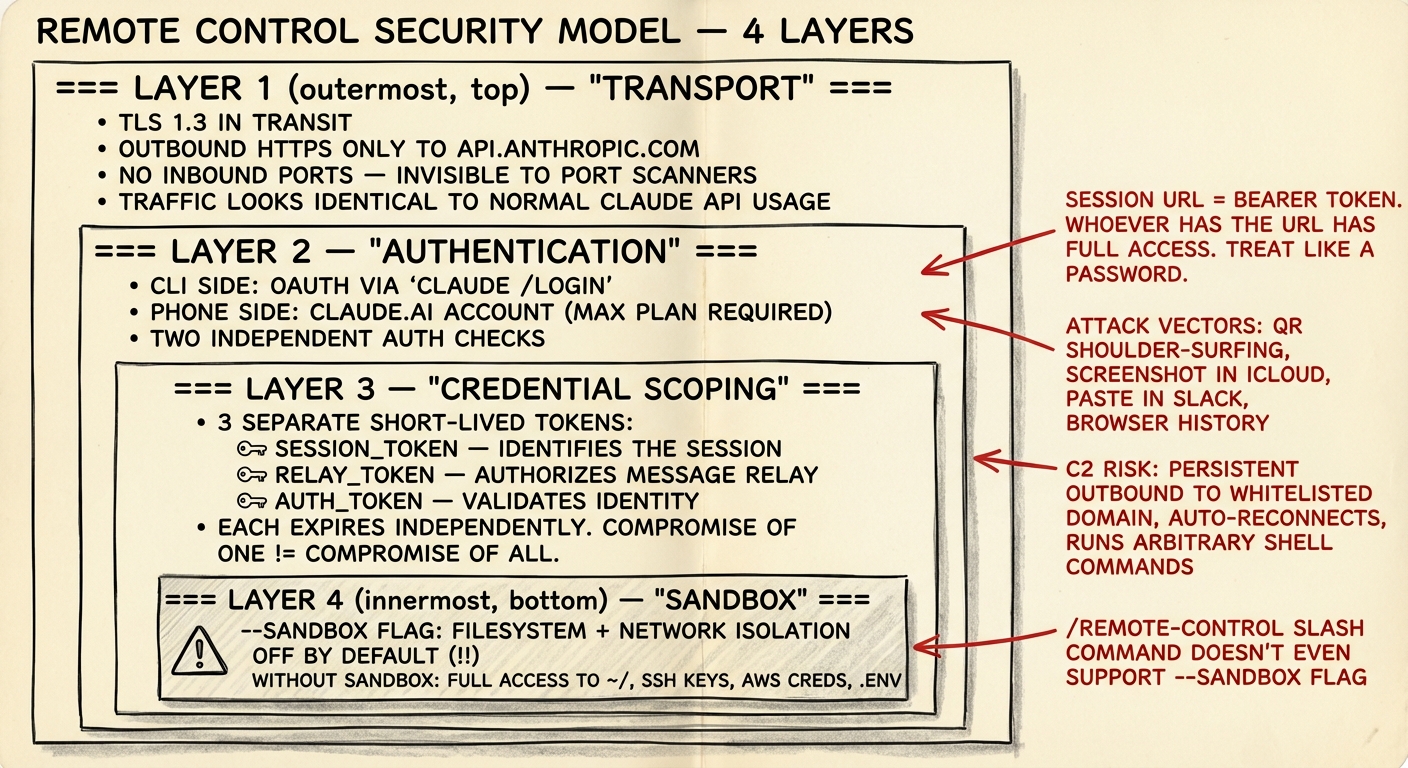
四层防御。三层是扎实的。一层出人意料地薄弱。
第一层:传输层
TLS 加密。仅出站 HTTPS 连接到 api.anthropic.com - 与常规 Claude API 调用使用同一域名。这意味着:
- 不需要特殊的防火墙规则
- 流量与正常 API 请求混在一起(既是优点也是隐患)
- 企业网络中白名单放行了
api.anthropic.com的代理会自动放行 remote control
第二层:身份认证
CLI 端通过 claude /login (OAuth) 认证。手机端需要 claude.ai Max plan 登录。两个独立的校验环节。
第三层:作用域凭证
多个短期 token,各司其职:
session_token- 标识会话relay_token- 授权消息中继auth_token- 验证身份
每个 token 独立过期。一个 token 泄露不会连带其他 token。
第四层:Session URL - 最薄弱的环节
"The session URL itself functions as a master authentication token... the 'skeleton key' granting full access regardless of credential rotation policies."
拿到 URL,就能操控会话。攻击路径包括:
- 二维码肩窥 - 咖啡店里有人拍下你的屏幕
- 截图泄露 - 你截屏二维码发给自己,结果同步到了 iCloud 照片流
- 浏览器历史 - URL 留在浏览历史记录里
- Slack 误发 - 你把 URL 发给同事"测试一下"
- 屏幕录制 - 结对编程时有人录了屏
C2 的影子
AgentSteer 还指出了一个结构性隐患:
persistent outbound connection -> legitimate domain -> auto-reconnect -> arbitrary shell execution
如果攻击者拿到了 session URL,就等于获得了一个类 C2 通道:合法的 anthropic.com HTTPS 连接,能穿透防火墙,能执行 bash,能访问 SSH 密钥和 .env 文件,还能在网络中断后自动重连。企业安全团队应当引起重视。
沙箱
# 启用沙箱(限制文件系统和网络访问)
claude remote-control --sandbox
# 默认:不启用沙箱
claude remote-control沙箱默认关闭。启用后,它会将文件系统访问限制在项目目录内,并限制网络访问。大多数人不会知道要手动开启。而且如果你在会话内用 /rc 启动 remote control,--sandbox 参数甚至不可用。
状态同步
当你的手机加入一个已经在运行的会话时,它需要获取完整的对话历史。如果 agent 正在执行工具调用并且有部分输出在流式传输,这并不简单。
根据 Agent SDK 的会话管理机制(它支持 --resume 并能完整重建历史),同步流程大致如下:
- 手机连接到 relay
- Relay 发送到目前为止累积的完整对话历史
- 如果 agent 正在执行中,streaming 事件继续推送给新连接的客户端
- CLI 持有权威状态;远程 UI 只是它的一个视图
这是一个 append-only log。对话是一系列事件的序列 - 用户消息、助手消息、工具调用、工具返回。Relay 存储这个日志。新客户端连接时获取完整日志,然后订阅新事件。
已知的同步问题:
- 重连后看到过时状态(显示几小时前的对话)
- 没有增量重同步机制 - 断连期间错过的事件,没有"给我序列号 N 之后的所有事件"这样的能力
- 客户端状态可能悄无声息地与 relay 状态产生偏移
正确的修复方案是为每个事件添加单调递增的序列号。客户端跟踪"我已经看到了 #47",重连时请求"#47 之后的所有事件"。Slack 和 Discord 就是这么做的。
延迟
一次远程命令的跳数:
手机 -> Anthropic relay -> CLI(本地)
~50ms ~10ms ~0ms
|
CLI 执行工具(例如 git diff)
~200ms
|
CLI -> Anthropic relay -> 手机
~10ms ~50ms
一次简单工具调用的完整往返延迟:大约 320ms。LLM 推理还会额外增加 1-30 秒,这才是真正等待的地方。
Relay 中转增加的延迟大约 60-100ms。对于一个用户输入 prompt 然后等待 AI 回复数秒的聊天界面来说,这几乎感知不到。系统在设计上就是延迟容忍的 - 它不是远程桌面,也不是游戏服务端。
同类系统对比
| Claude Code RC | VS Code Tunnels | Tailscale DERP | ngrok | |
|---|---|---|---|---|
| 中继内容 | 应用层消息 | 网络流量 | 网络数据包 | TCP 流 |
| 认证方式 | Session URL + 账户 | GitHub/MS 账户 | WireGuard 密钥 | Auth token |
| 加密 | TLS(声称 E2E) | TLS | WireGuard(真正的 E2E) | TLS |
| 重连 | < 10 分钟自动重连 | 自动 | 自动 + 直连升级 | 可配置 |
| 开源 | 否 | 部分 | 是(DERP 服务端) | 否 |
| 攻击面 | 仅聊天 + 工具 | 全网络 | 全网络 | 全网络 |
Claude Code 的攻击面比基于隧道的方案更小(仅结构化消息),但认证模型比 Tailscale(WireGuard 密钥交换)或 VS Code(GitHub 账户 + 设备绑定)更弱。
我会改什么
如果让我设计 Remote Control v2:
设备绑定 - 将 session URL 与设备指纹绑定。扫描二维码时触发一个包含手机设备认证(Apple DeviceCheck / Android SafetyNet)的 challenge-response。泄露的 URL 在其他设备上将变得毫无用处。
双向心跳 - relay 向所有客户端推送连接健康状态:
{"type": "heartbeat", "cli_last_seen": "2026-02-26T10:00:05Z", "latency_ms": 47}事件序列号 - 每个事件携带一个单调递增的序列号。客户端跟踪自己的位置。重连时从断点继续。彻底消除应用重启后的过时状态问题。
默认启用沙箱 - 翻转默认值。claude remote-control 默认启用沙箱。需要完整访问权限的用户主动用 --no-sandbox 解除限制。
Session TTL - 可配置的会话生命周期。claude remote-control --ttl 2h 表示无论连接状态如何,会话在 2 小时后自动过期。
动手试试
# 最常用:在运行中的会话内启动
/rc
# 或者从 CLI 启动新会话
claude remote-control
# 启用沙箱(推荐首次尝试时使用)
claude remote-control --sandbox
# 开启详细日志(查看协议细节)
claude remote-control --verbose用手机扫描二维码,输入指令,看你的终端在本地执行。
值得测试的场景:
- 关闭笔记本 Wi-Fi 30 秒后再开。会话还活着吗?
- 关闭 Wi-Fi 11 分钟。
- 在手机上强制退出 Claude 应用再重新打开。对话还在吗?(大概率不在。)
- 在两个浏览器标签页同时打开 session URL。
- 把 session URL 发给一个拥有 Max plan 的朋友。他能连上吗?
真正的工程决策就隐藏在这些边界场景中。
结语
Remote Control 是一个基于 relay、仅出站连接的消息桥接方案,连接你本地的 CLI 和远程 UI。不是网络隧道。这一个设计选择决定了一切:安全模型、延迟特征、攻击面、功能边界。
v1 是扎实的工程成果。扫个二维码就能进入一个可用的会话,确实令人印象深刻。但工程接缝清晰可见:单向心跳、缺失的序列号、默认关闭的沙箱、作为万能钥匙的 session URL。全部可以修复。
如果你在构建 agent 基础设施 - 不是在用它,而是在造它 - 仔细研究这个设计。Relay 模式、作用域凭证、应用层消息转发:这些都是生产级 agent 系统的基础构件。而那些失败模式 - 过时状态、静默断连、URL 即 bearer token - 正是你不提前思考就会在自己系统里写出的 bug。